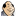Dieses Demo berechnet ein sogenanntes Apfelmännchen,
dessen numerische Berechnung sich leicht parallelisieren lässt.
Bis zu vier Threads, in je einer anderen Programmiersprache
kodiert, errechnen einen horizontalen Teilbereich dieses fraktalen Gebildes.
Mit Hilfe der Maus kann ein beliebiger Bereich dieser Grafik
vergrößert werden:
- Wenn sich der Mauszeiger
über der fraktalen Grafik, beschriftet mit Apfelmännchen,
befindet, erscheint ein Fadenkreuz.
-
Drücken Sie die linke Maustaste, um die linke obere Ecke des zu
vergrößernden Bereichs festzulegen.
Bewegen Sie nun den Mauszeiger zur gewünschten rechten unteren Ecke des
zu vergrößernden
Bereichs und drücken Sie noch einmal die linke Maustaste.
- Nun wird der Wertebereich des Apfelmännchens
dem ausgewählten Rechteck entsprechend neu
berechnet.
-
Alternativ kann der Wertebereich auch manuell
über die entsprechenden Eingabefelder geändert werden.
-
Mit der Schaltfläche Berechnen wird nun ein
dem geänderten Wertebereich entsprechendes Apfelmännchen generiert.
-
Die Schaltfläche Zurücksetzen
stellt den ursprünglichen Wertebereich und die entsprechende Grafik wieder her.
Java Source:
/*
* fractal demo
* written by Peter Sauer
* ScienceSoft 2003,2004
*/
public int[] doCalc(
int yOffset,
int lines,
int width,
int maxIter,
double xStart,
double xZoom,
double yStart,
double yZoom) {
int buffer[] = new int[lines * width];
int index = 0;
for (int y = yOffset; y < yOffset + lines; ++y) {
double tmp = yStart + yZoom * (double) y;
for (int x = 0; x < width; ++x) {
double r = 0.0, i = 0.0, m = 0.0;
int iter = 0;
while ((iter < maxIter) && (m < 4.0)) {
m = r * r - i * i;
i = 2.0 * r * i + tmp;
r = m + xStart + xZoom * (double) x;
++iter;
}
buffer[index++] = iter * iter;
}
}
return buffer;
}
C Source:
/*
* fractal demo
* written by Peter Sauer
* ScienceSoft 2003,2004
*/
JNIEXPORT jintArray JNICALL Java_fractal_NativeCWorkerThread_doCalc(
JNIEnv *env, jobject obj,jint yOffset, jint lines, jint width, jint maxIter,
jdouble xStart, jdouble xZoom, jdouble yStart, jdouble yZoom) {
jint *buffer = (jint *)malloc(lines * width * sizeof(jint));
jint index = 0;
jint y,x;
jintArray array;
jint end = yOffset + lines;
if(!buffer) {
return NULL;
}
for(y = yOffset; y < end ; ++y) {
jdouble tmp = yStart + yZoom * (double) y;
for (x = 0; x < width; ++x) {
jdouble r = 0.0, i = 0.0, m = 0.0;
jint iter = 0;
while ((iter < maxIter) && (m < 4.0)) {
m = r * r - i * i;
i = 2.0 * r * i + tmp;
r = m + xStart + xZoom * (jdouble) x;
++iter;
}
buffer[index++] = iter * iter;
}
}
array = (*env)->NewIntArray(env,index);
if (array == NULL) {
free(buffer);
return NULL;
}
(*env)->SetIntArrayRegion(env,array,0,index,(jint *)buffer);
free(buffer );
return array;
}
FORTRAN77 Source:
c
c fractal demo
c written by Peter Sauer
c
integer function fcalc(array,yoffset,lines,width,maxiter,xstart,
& xzoom,ystart,yzoom)
implicit none
integer array(*)
integer yoffset,lines,width,maxiter
double precision xstart,xzoom,ystart,yzoom
integer y,x
integer size
double precision tmp
double precision r,i,m
integer iter,index
size = yoffset + lines
y = yoffset
index = 1
while(y .lt. size) do
tmp = ystart + yzoom * y
x = 0
while (x .lt. width) do
r = 0.0
i = 0.0
m = 0.0
iter = 0
while((iter .lt. maxiter) .and.
& (m .lt. 4.0)) do
m = r * r - i * i
i = 2.0 * r * i + tmp
r = m + xstart + xzoom * x
iter = iter + 1
end while
array(index) = iter * iter
index = index + 1
x = x + 1
end while
y = y + 1
end while
fcalc = index
end
Assembler Source:
/*
* fractal demo
* written by Peter Sauer
* ScienceSoft 2003,2004
*/
JNIEXPORT jintArray JNICALL Java_fractal_NativeASMWorkerThread_doCalc(
JNIEnv *env, jobject obj,jint yOffset, jint lines, jint width, jint maxIter,
jdouble xStart, jdouble xZoom, jdouble yStart, jdouble yZoom) {
jint size = lines * width;
jint *buffer = (jint *)malloc(size * sizeof(jint));
jintArray array;
jint end = yOffset + lines;
int x;
int four = 4;
if(!buffer) {
return NULL;
}
_asm {
push esi // save all working registers
push edi
push eax
push ebx
push ecx
push edx
finit
mov esi,buffer // load image buffer address
mov edi,yOffset // load y-offset
fld xZoom
fld xStart // push xStart
yloop:
xor ebx,ebx // x value counter
mov x,ebx // save x value
// pre-calculate: tmp = yStart + yZoom * (double) y;
fld yStart // push yStart st
fild yOffset // push y-value st(1)
inc yOffset // increment y-value
fld yZoom // push yZoom
fmul // st = yZoom * (double) y
fadd // st = yStart + yZoom * (double) y
xloop:
xor ecx,ecx // iter = 0
fldz // i = 0
fldz // r = 0
iteration:
fld st(1) // push i
fld st
fmul // st = i * i
fld st(1) // push r
fld st
fmul // st = r * r
fsubr // m = r * r - i * i;
ficom four // m < 4?
fstsw ax
sahf
ja quit_iteration
fld st(1) // push r
fmulp st(3),st // i = i * r
fld st(2) // push i * r
faddp st(3),st // i+= i
fld st(3) // push yStart + yZoom * (double) y
faddp st(3),st // i+= yStart + yZoom * (double) y
fstp st(1)
fld st(3) // push xStart
fadd
fld st(4) // push xZoom
fild x // xZoom * x
fmul
fadd // r+= xZoomm * x
inc ecx // inc iter
cmp ecx,maxIter // iter < maxIter?
jl iteration
jmp skip
quit_iteration:
inc ecx
fstp st(0) // remove m from stack
skip:
fstp st(0) // remove i from stack
fstp st(0) //
mov eax,ecx // iter
mul ecx
mov [esi],eax // store color value
add esi,4 // increment memory index
inc x
inc ebx // increment x
cmp ebx,width // x < width
jl xloop
inc edi
cmp edi,end
fstp st(0) // remove tmp from stack
jl yloop // y < end
pop edx
pop ecx
pop ebx
pop eax
pop edi
pop esi
}
array = (*env)->NewIntArray(env,size);
if (array == NULL) {
free(buffer);
return NULL;
}
(*env)->SetIntArrayRegion(env,array,0,size,(jint *)buffer);
free(buffer);
return array;
}
Bemerkungen
Bei der Interpretation der Thread-Laufzeiten müssen folgende
technische Gegebenheiten berücksichtigt werden:
-
Da diese Demonstration auf einem Einprozessorsystem läuft, bringt die Parallelisierung
in Form von Threads keinen Geschwindigkeitsvorteil.
-
Die in C, FORTRAN77 und Assembler kodierten
Threads müssen - im Gegensatz zum Java-Thread - die berechneten Grafikdaten
per JNI (Java Native Interface) an das Servlet weiterreichen.
Diese Interaktion kann bei den kurzen Rechenzeiten die Geschwindigkeitsvorteile
der nativen Programmiersprachen gegenüber dem JIT (Just In Time)
Java-Code nivellieren.
-
Apfelmännchen, die mit Hilfe des manuell kodierten Assembler-Codes berechnet werden,
können sich in feinen graphischen Details von den
Ergebnissen der anderen Programmiersprachen (Java, C und FORTRAN77) unterscheiden.
Der Assembler-Code führt durchgehend die
Berechnungen mit 80-Bit-Genauigkeit über den Stapelspeicher der FPU (Floating Point Unit)
durch, während der compilierte Code der anderen Programmiersprachen Zwischenergebnisse der FPU im
Speicher (2*32 = 64 Bit) ablegt. Da ein Punkt des Apfelmännchens durch eine
Rekursion bestimmt wird, kann sich der Unterschied in der Rechengenauigkeit (64/80 Bit)
in Form einer unterschiedlichen Punktfarbe auswirken.
Mathematischer Hintergrund
Dieses bekannte fraktale Gebilde basiert auf der einfachen rekursiven Funktion
z = z2 + c mit einem Startwert z0 = 0
und c als Konstante. z und c entsprechen komplexen Zahlen, die
auch als Punkte in der Ebene dargestellt werden können. Für die
Berechnung wird nun diese Rekursion für eine endliche Punktmenge
aus dieser Ebene durchgeführt. Die Rekursion eines Punktes kann folgende
Verhaltensweisen zeigen:
-
Die Werte eines Punktes verlassen ein bestimmtes Intervall nicht - die Werte bleiben
endlich. In diesem Fall gehört der Punkt zur sogenannten
Mandelbrot-Menge*, und es wird ihm
die Farbe Schwarz zugeordnet.
-
Streben die Werte des Punktes ins Unendliche, dann ist der Punkt kein
Element der Mandelbrot-Menge, und seine Farbe wird in Relation zur Anzahl der Iterationen gesetzt, nach denen
seine Werte ins Unendliche streben.
* Die Menge ist nach dem französischen Mathematiker Benoît Mandelbrot benannt,
der als erster diese Art von Bildern mit Hilfe eines Computers erstellte.